

时间:2022-08-04
1
构建背景
现阶段国内各行业标准知识的供给方式大多停留在传统纸质标准及简单PDF全文检索的阶段,标准知识检索效率低、标准之间关联程度弱,难以满足产品研制单位对标准知识高效供给的需要。标准知识图谱是通过标准本体构建、信息抽取、知识融合、知识更新等环节建立起来的结构化标准知识库,能够建模标准内部详实的知识单元以及标准之间大规模的语义关联,典型的产品标准知识体系示意如图1所示,通过结构化检索、关联查询等方式能够实现标准知识的智能供给,满足产品研制单位对于标准知识的智能化应用需求。

图1 产品标准知识体系示意图
针对标准知识的精准查询过程如图2所示,首先将标准文本当中的知识条目通过信息抽取等方式抽取为多个结构化知识单元,并将其建图存储在结构化数据库中,其中每一个知识单元是由一对实体及实体间的关系所组成,如文本“收油头主要由转刷、刮油器、集油槽、传输泵及相关支撑结构组成。转刷主要由刷毛、传送带等部件组成。”中,主要描述对象为船用刷式收油机的其中一个组件“收油头”,则“收油头”即为待抽取知识单元的主实体,主要介绍内容为收油头的结构组成,那么文本“转刷、刮油器、集油槽、传输泵及相关支撑结构组成。”即为描述“收油头”的客实体,根据语义分析可知,主实体与客实体之间的关系为“结构组成”。当将传统的文本字符串建模成图结构化的语义知识关联后,便能够通过对用户输入问题的结构化分析,将用户问题转化为多个实体及关系的结构化查询词语并触发映射到结构知识库中的实体及关系词,最终精准获取当前用户输入问题的对应答案,彻底摆脱传统的纸质标准翻阅及PDF检索翻阅等标准知识查询方式。
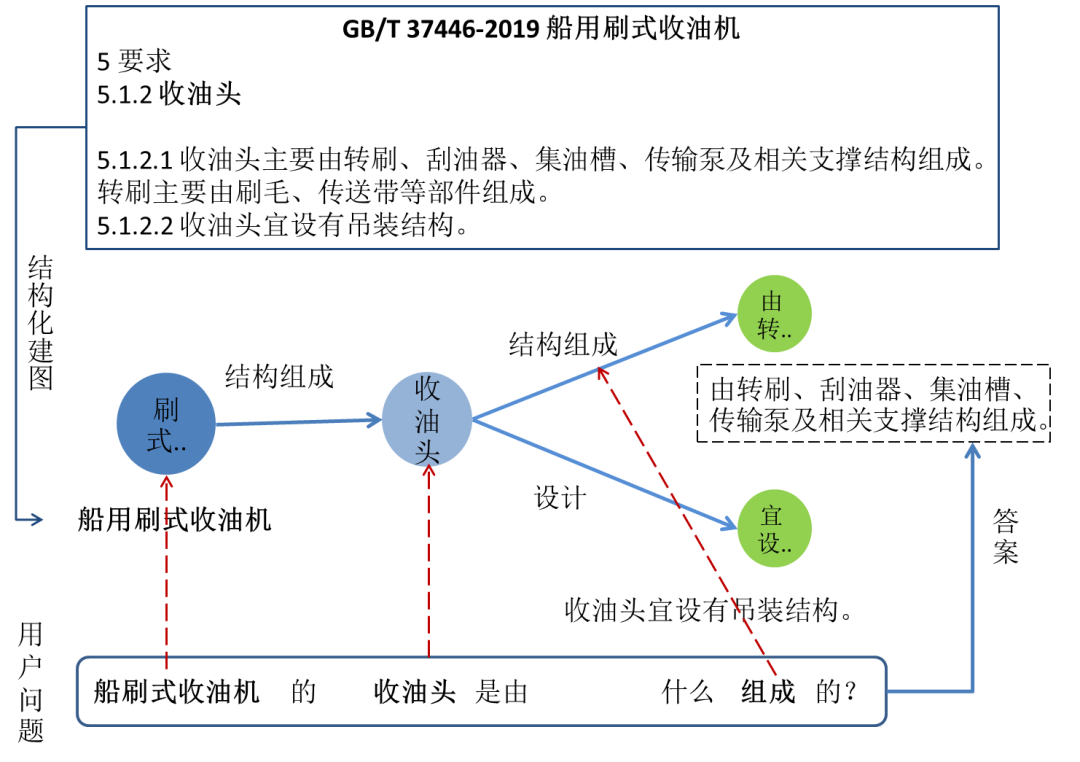
图2 标准知识精准检索示意图
然而在处理“技术要求”一章时,要将全部研制过程所需的产品标准技术要求知识都建模成为以“标准化对象”为核心节点(头实体)、以技术要求(通常为小标题)为“关系”、以技术要求内容为客实体的知识图谱结构(如图3所示),需要首先解决两个主要问题,其一是技术要求命名不统一,导致用户在输入端难以通过规范化用词查询到非规范化命名的技术要求内容;其二是核心技术要求章节内容排布方式不统一,导致并非每一条技术要求内容都有显式的技术要求小标题用于确定结构化三元组中的“关系”。
技术要求命名不统一指的是不同专家在进行标准编制时,在对某些产品做出相同方向技术要求规定时,由于编制用词习惯的问题,导致技术要求用词不一致,如图3(a)与图3(b)分别是对船用柴油机盘车机与船用柴油机电子调速器在温度方面的相关规定,然而如图3(b)所示,文本中此条目用词为“环境温度”,倘若直接以“环境温度”为关系构造以“船用柴油机电子调速器”为主实体,对应技术要求内容为客实体构造结构化知识单元进行存储的话,用户在查询时便无法在未知关系词的情况下,以规范化技术要求词“温度”将目标内容检索出来,因此需要将图3(b)中“环境温度”通过人工和机器自动化分类相结合的方式归一化为“温度”以实现在用户侧通过规范化用词实现全知识库的精准检索及关联查询。

(a) (b)
图3 技术要求命名示意图
核心技术要求章节内容排布方式不统一指的是按照现有的知识组织方式,需要将技术要求内容作为客实体,通过某个技术要求词汇(通常为小标题)作为关系(边)挂接到主实体上,然而由于不同编制者的编制习惯以及不同产品的特殊性,导致很多技术要求内容并未直接以小标题的方式告知用户当前内容属于对描述对象哪一方面的技术要求规定,如图2所示,又如图4,并未显式的告知用户当前技术要求内容属于哪一方面的性能要求。因此我们需要为图2中的技术要求内容通过人工或机器自动化分类的方式赋一个专业性强的“关系词”,也需要为图4中的技术要求内容赋一个粒度更细的技术要求关系词。
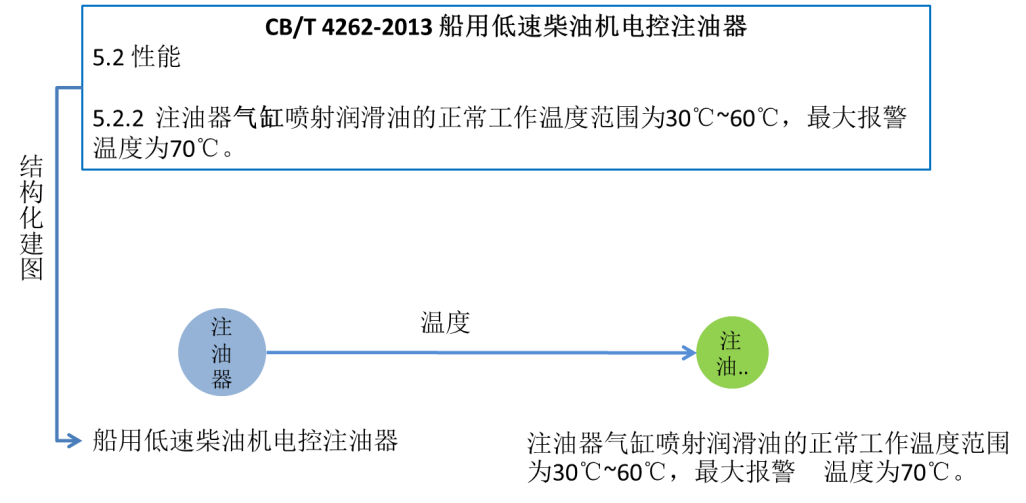
图4 内容排布不统一示意图
2
构建过程
为将全部研制过程所需的标准知识构建成为标准知识图谱,且考虑到人工标注成本高、代价大,故而需要进行自动化技术要求分类算法的开发,将上述图2、图3(b)、图4中的无显式技术要求小标题规定或无规范化技术要求小标题规定的技术要求内容自动赋以专业性高、使用普遍性强的技术要求词(关系词),为此需要进行有监督的面向深度学习算法的产品标准技术特性分类数据集的构建。
1)数据收集
首先将标准文本固有的组织方式与行文特征模式化为计算机可理解的规则和模板,利用规则和模板将产品标准中技术要求的内容进行单独抽取,并将每一条样本整理成如下格式的计算机字典类型数据:{输入:盘车机减速器润滑油温升不大于35℃,最高油温不大于95℃,输出:温度},对所有样本进行初步的数据统计,共根据模板与规则判断并处理word格式船舶产品标准820份,抽取出如上述格式的输入输出键值对20066个,其中技术要求词未出现在描述内容中的样本数为11783个,出现的不同技术要求词或小标题数3845个,出现次数大于5次的技术要求为147个,考虑到出现次数较少的技术要求内容大多是针对于某些产品的特定技术要求描述,所以我们并不将此类针对于特定产品的描述纳入到数据集当中来,在对输出词(技术要求词)进行归一化处理,将数据集进行进一步分类规整后,作为用于算法开发的最终的有监督数据集。
2)归一化处理
本文中以两种相似度计算方法,即:基于编辑距离的字符串相似度计算方法与基于预训练语言模型与余弦相似度的相似度计算方法并分别辅以专家总结校核进行3845个技术要求词的归一化处理。
编辑距离或者莱文斯坦距离指两个字串之间,由一个转换成另一个所需的最少编辑操作(插入、删除、替换)的次数。基于余弦相似度的方法指的是加载预训练语言模型,为每一个技术要求词汇获取一个预训练好的固定维度的稠密向量,随后为每一个技术要求词汇遍历所有词列表,并进行两个词汇之间的相似度计算,保留相似度大于0.5的近义词对,最终将近义词对交由专家进行审核校正,最终生成待归一化的同义、近义词表,部分同义、近义词表如表1所示,我们会将数据集中所有同义词及可归一化的近义词规范化为统一表述,重新存储在数据集当中。
表1 待归一化同义、近义词表

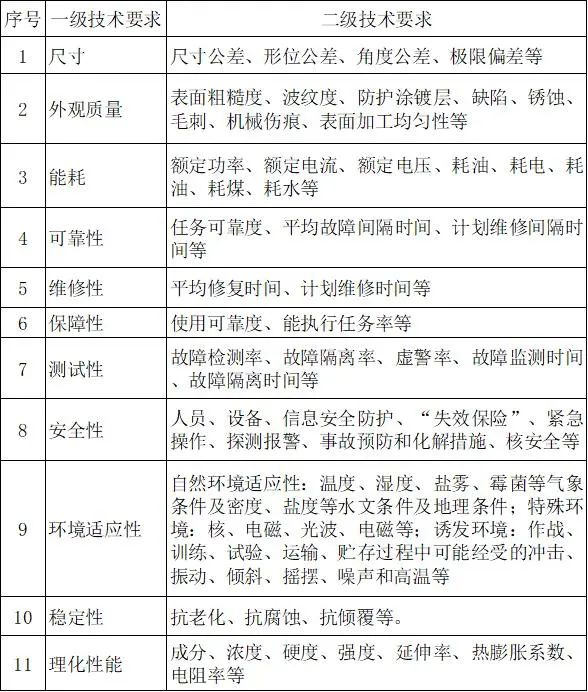
表2列出了部分通常会进一步细化规定的部分技术要求,除此之外还有诸多无需典型细化的技术要求如:材料、重量、耐久性、互换性、接口、运输性、人机工程、标志、包装、贮存、运输等产品需做出规定的重要技术要求。值得说明的是除尺寸、测试性、及环境适应性对应的二级技术要求之外,我们并不将细化的技术要求作为数据集中的独立输出,而是将二级技术要求暂时规范化为一级技术要求词并存储到数据集当中,如将{输入:不锈钢家具的主要尺寸应符合CB/T 3231.1~.9-2014的要求。不锈钢家具的台面厚度应不小于1.2mm,侧板厚度应不小于0.8mm。输出:尺寸公差}规范化为{输入:不锈钢家具的主要尺寸应符合CB/T 3231.1~.9-2014的要求。不锈钢家具的台面厚度应不小于1.2mm,侧板厚度应不小于0.8mm。输出:尺寸}。
表2 分级技术要求表
在对数据进行进一步去噪、归一化、去除技术要求出现次数较少的小样本之后,共获取规范化数据样本5836条,并于表3中列举出了部分样本示例,所涵盖的技术要求种类为51种,表4列举出了出现次数前十及后十的技术要求及对应出现次数,可以看出在船舶制造领域技术特性抽取数据集中存在着较为严重的数据偏置问题。
表3 数据集部分样本示例
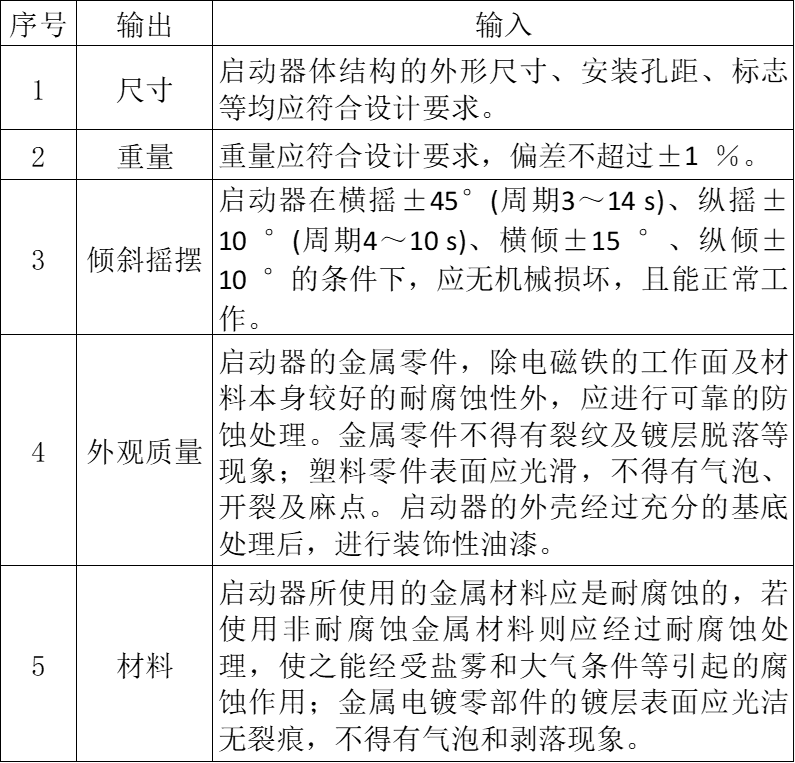
表4 技术要求统计特征表

3
构建意义
有监督的技术特性分类数据集的构建能够对技术要求命名的规范化起到一定的支撑作用,并可基于此数据集进行深度学习算法模型的开发,为诸多无显式技术要求说明的内容以及命名不规范的技术要求内容进行重新分类,以支撑产品标准知识图谱的顺利构建,可以让用户直接以常用词进行全标准知识数据库的统一检索与关联分析,进一步满足产品研制过程中对于标准知识的智能化应用需求。
END
作者 | 郑佳明
编辑 | 赵晨宁
(来源:公众号中国船舶标准化)
 电话:4008670886 /
电话:4008670886 /  English
English





 4008670886
4008670886